Hello,
This will be a continuation from my other topic here:
I have run more test and i think i have narrowed down where the problem is being generated.
For my latest tests i decided to go back to previous versions to see if there was some point where it worked as expected. As 4.2 seemed to have several changes on the subject i started in 4.1 with a complete clean install, then making copy of volumes and trying 4.2 and 4.3
For this test i created PDF files with 1, 100, 1000 and even 5000 pages each and uploaded several by api to get a good amount of pages since that was one of the main factors in my previous test.
Main conclusions from my tests:
1-Confirmed that 4.1 works correctly and problems start with 4.2
2-I also found that there are 2 problems that comes with 4.2 regarding many unwanted/needed tasks.
3-The main issue seems to not be with number of documents of the same type but with the amount of documents in the same cabinet.
How i got to those conclusions.
-I first uploaded a lot of documents with large amount of pages up to having around 150k pages from documents of the same type. I targeted this amount as is big enough to see the problems and not that big that each test would require me to wait too much between each one.
-With 4.1 i could not found a way to accumulate many tasks on the search queue.
-After 4.2 upgrade i did found an increase, but it was not what i experienced on my other setups. Here i found the extra problem i mentioned in point ‘2’, and the only reason i found it is because i was uploading documents with artificial large amount of pages. For some reason a document of 1k pages generates around 40k task, mostly of ‘documentfilepage’. Tested that increasing the number of pages increases tasks proportionally. Considering 1k pages i would have expected 2k page related tasks (ocr+pdf2text), around 20 times more seems off.
-4.3 Was the same and i was about to try 4.4 again when i realized my test implementation was just too basic: I was only uploading documents and at most only using the included index.
-I created a cabinet and that is when real problems begin. Still being in 4.3 i moved 40 documents (around 45k pages total) to a cabinet and the queue went to almost 3 Million tasks.
-Looking at the task many at first were of different kind, then most became the regular offenders of file and version pages.
-Subsequent uploads would show that the amount of tasks would be around 2 times the total amount of pages on the cabinet, some as my past finds but now i see the scope was the cabinet and not the document type.
-After that, i went back to 4.1 and started testing with cabinets.
-Here are a couple graph from rabbitmq web console that illustrate the problems.
4.1, manually adding four 5k documents to the same cabinet, one after the other once queue was cleared.
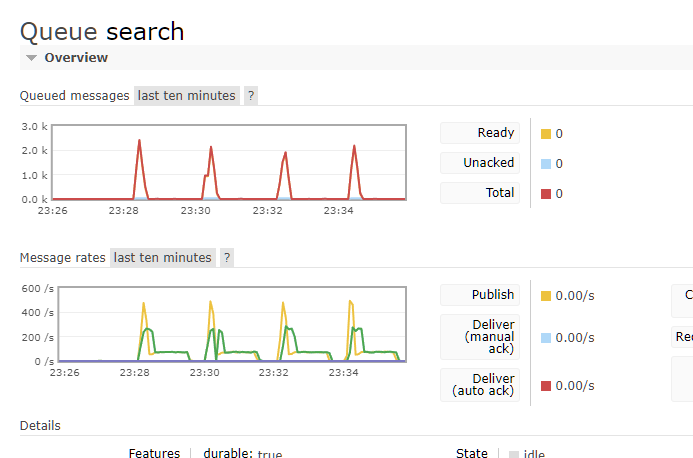
Notice how it is almost like clockwork besides increasing the total amount of pages in the cabinet.
Now, a similar test with 4.2 Here i used 1k documents because 5k took just too much time to clear:
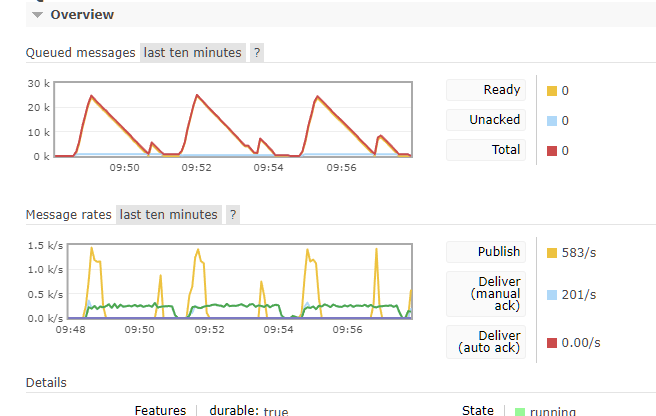
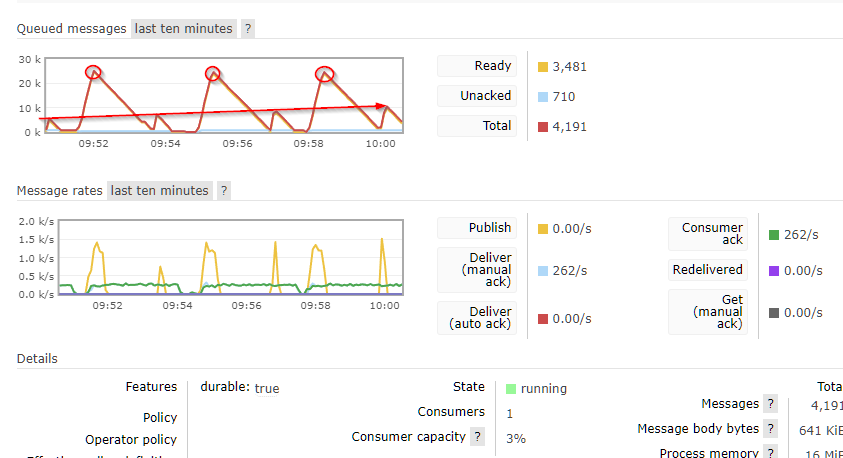
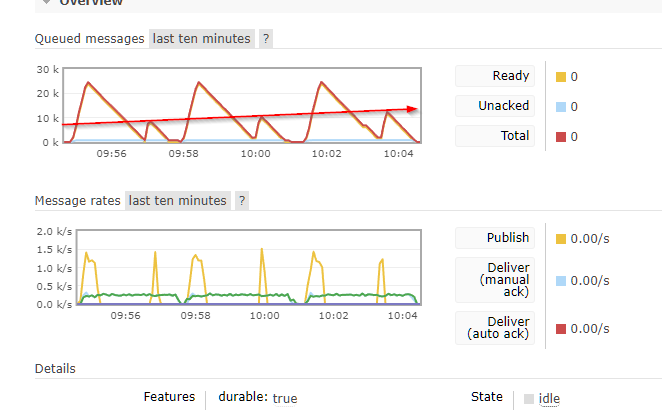
Here both problems i found can be observed.
First is that besides uploading only 1/5 the amount of pages each time, a lot more tasks are generated (circles on the peaks)
The second, is that one can see each upload (only 3 per 10 min timeframe) generates two spikes. The one with the circle and the ‘small’ one that you can see how it goes bigger on each subsequent upload.
That last one is the real problem i have been dealing with all this time. Those example images are starting with clean cabinet, buts once it starts populating it becomes a massive problem: disks full, memory swap/dumps, constant need to purge queue by cron. All because of tasks that should not be there in the first place: Adding a document to a cabinet does not change anything from Text extraction or OCR from other documents.
So, i think i have narrowed this thing a lot. Sadly, 4.2 introduced massive amount of changes, and tracking down in code were it went wrong is too complex task for me. I may understand coding to a degree, but i’m SysAdmin not a Developer.
I’m open to help if more tests are required.
Thanks