Yes it can be done.
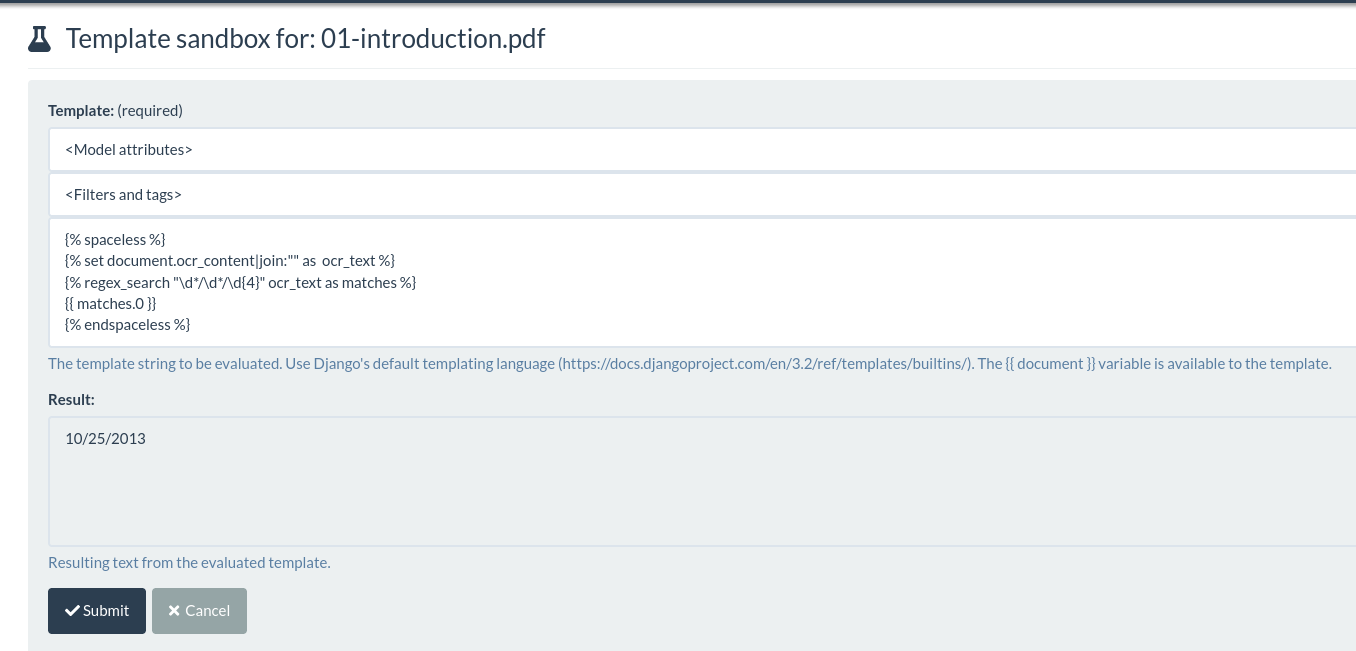
{% spaceless %}
{% set document.ocr_content|join:"" as ocr_text %}
{% regex_search "\d*/\d*/\d{4}" ocr_text as matches %}
{{ matches.0 }}
{% endspaceless %}
This template will match a regular expression against the OCR content and produce all matches. You can then select the first (or any or all dates) and use it for indexing or store it as metadata using a workflow action.
By changing the regular expression this same snippet can be reused for many scenarios.