I have tested indexing by OCR content and it worked perfectly. However, I am wondering if the documents can also be assigned to a specific cabinet based on the OCR content. If that is not possible, I would also consider assigning the documents to a specific cabinet based on their indexing as a workaround (using API). Does anyone have experience with this?
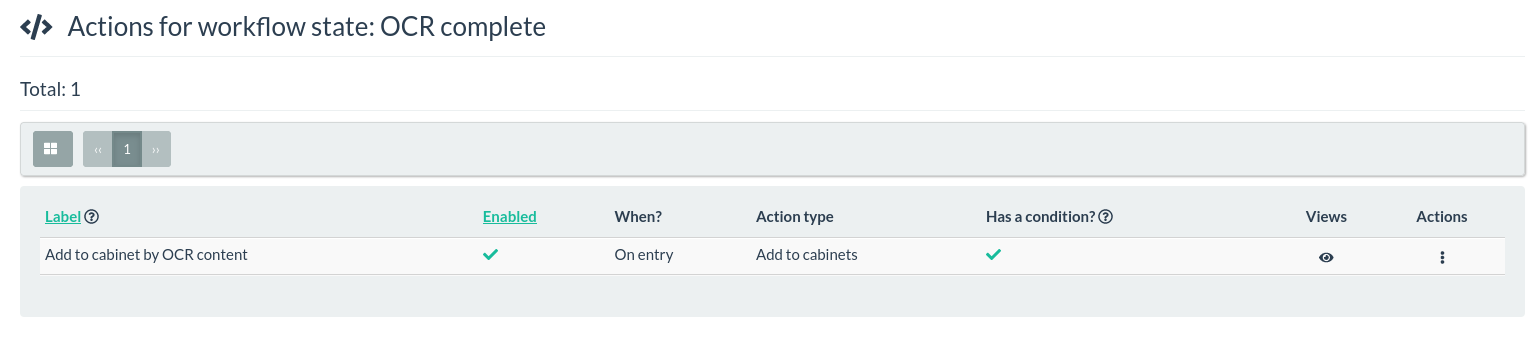
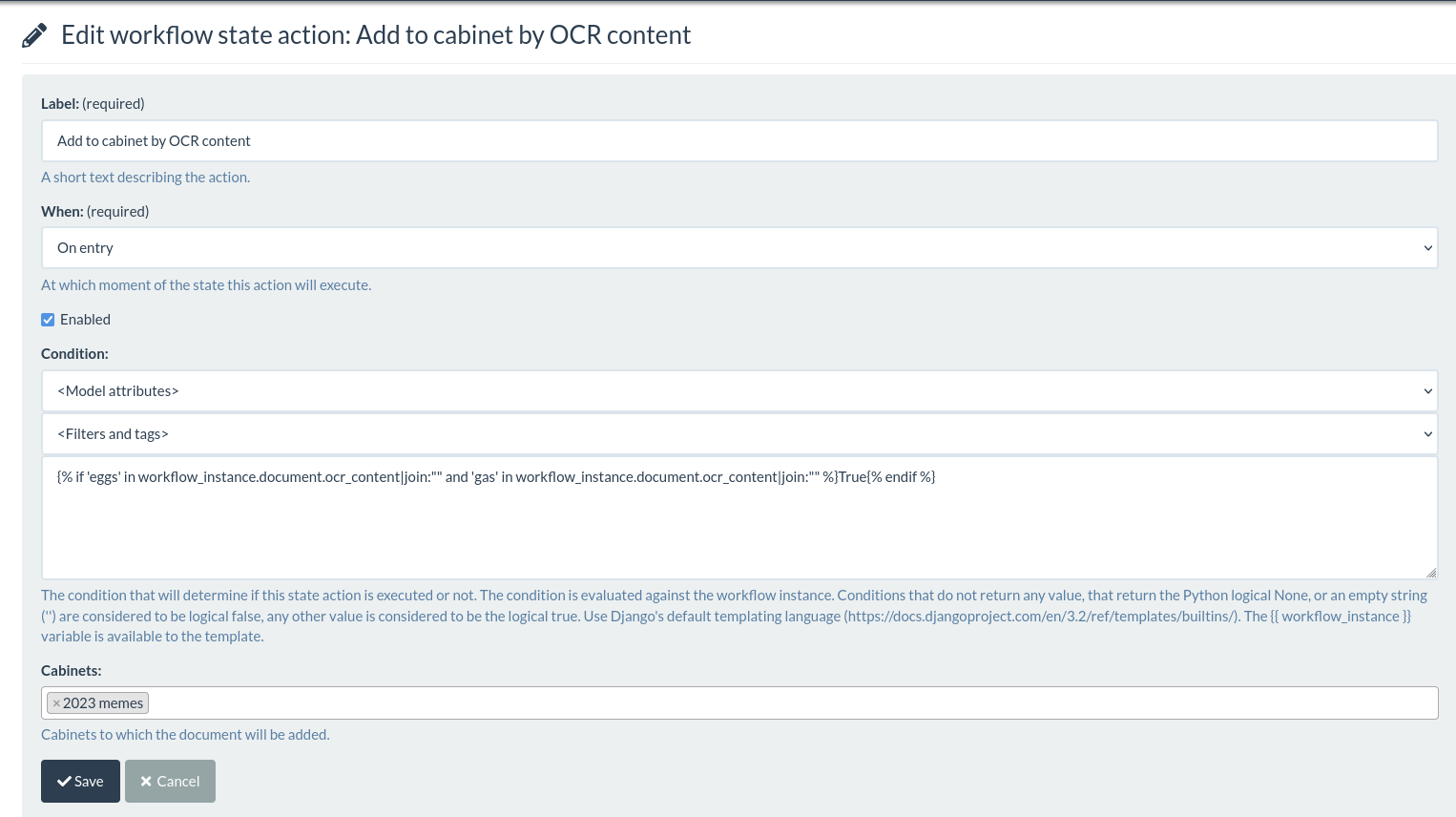
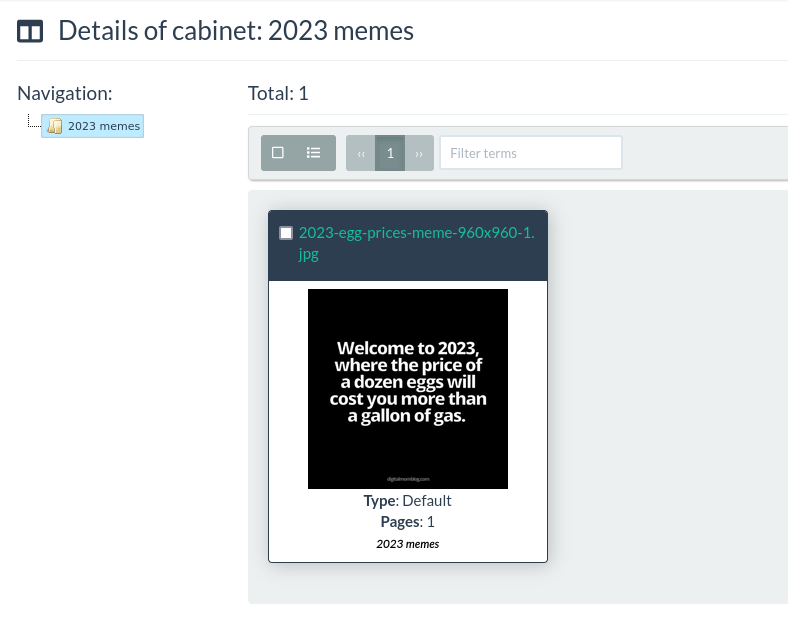
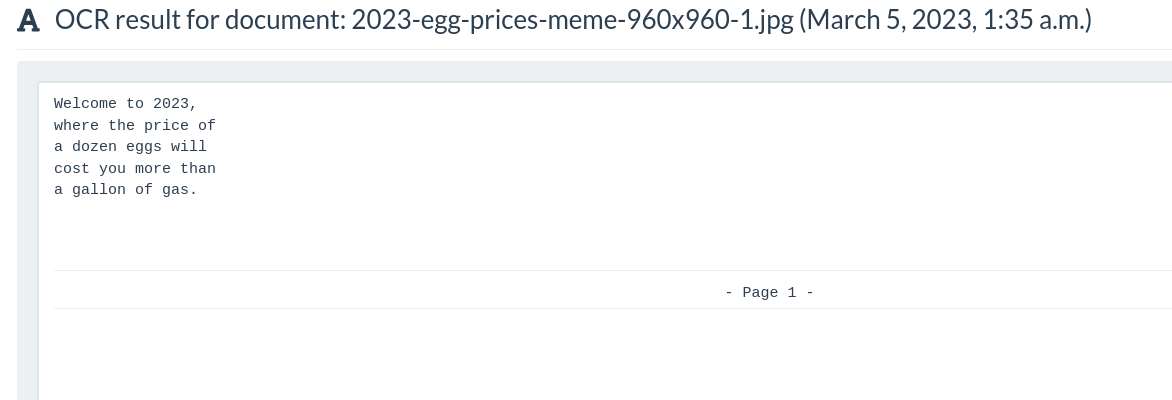
The best way to do this is with a workflow. In this example I’ll place an image in the “2023 memes” cabinet if they have the words ‘eggs’ and ‘gas’ in the OCR text.
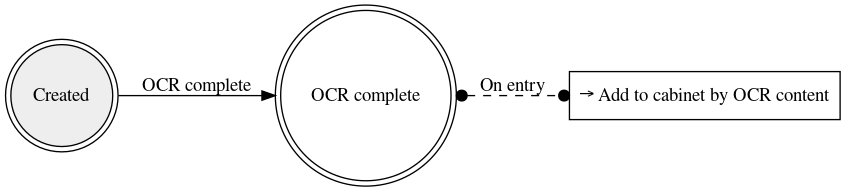
a. Two states: created and OCR complete.
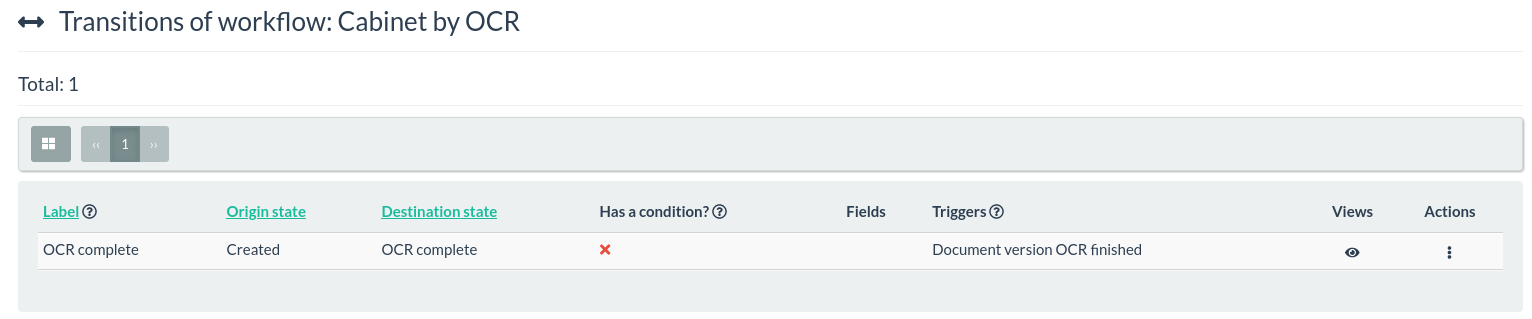
b. Add a single transition from created to OCR complete.
c. Set the transition trigger to be the OCR complete event.
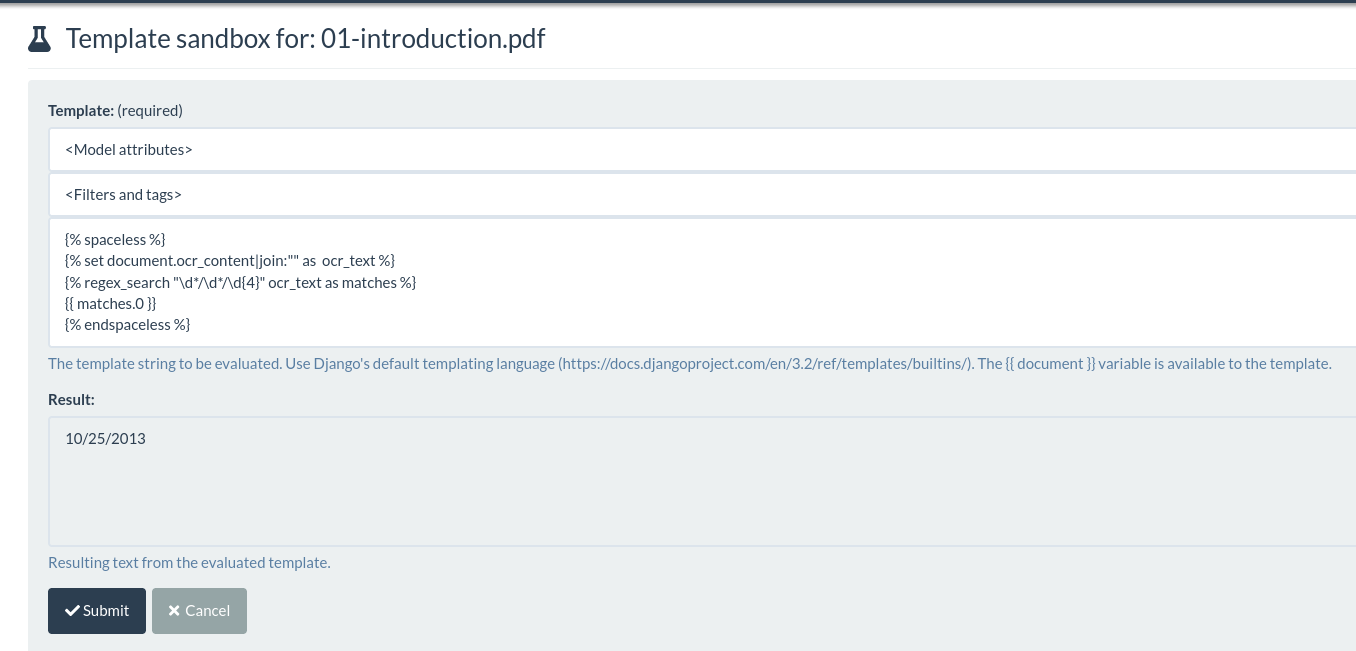
{% spaceless %}
{% set document.ocr_content|join:"" as ocr_text %}
{% regex_search "\d*/\d*/\d{4}" ocr_text as matches %}
{{ matches.0 }}
{% endspaceless %}
This template will match a regular expression against the OCR content and produce all matches. You can then select the first (or any or all dates) and use it for indexing or store it as metadata using a workflow action.
By changing the regular expression this same snippet can be reused for many scenarios.
Thanks, in the meantime I came up with practically the same templating.
{% regex_search "[0-9]{1,2}(\.|\-|\/)[0-9]{1,2}(\.|\-|\/)[0-9]{4}" document.content|join:"" as date %}
{{ date.group | date_parse | date:"d-m-Y" }}
I’ve put this into a Workflow with “parsing completed” as a trigger, and I have date filler that works at least 70% of all time—letter and receipt would have date somewhere on the top part.
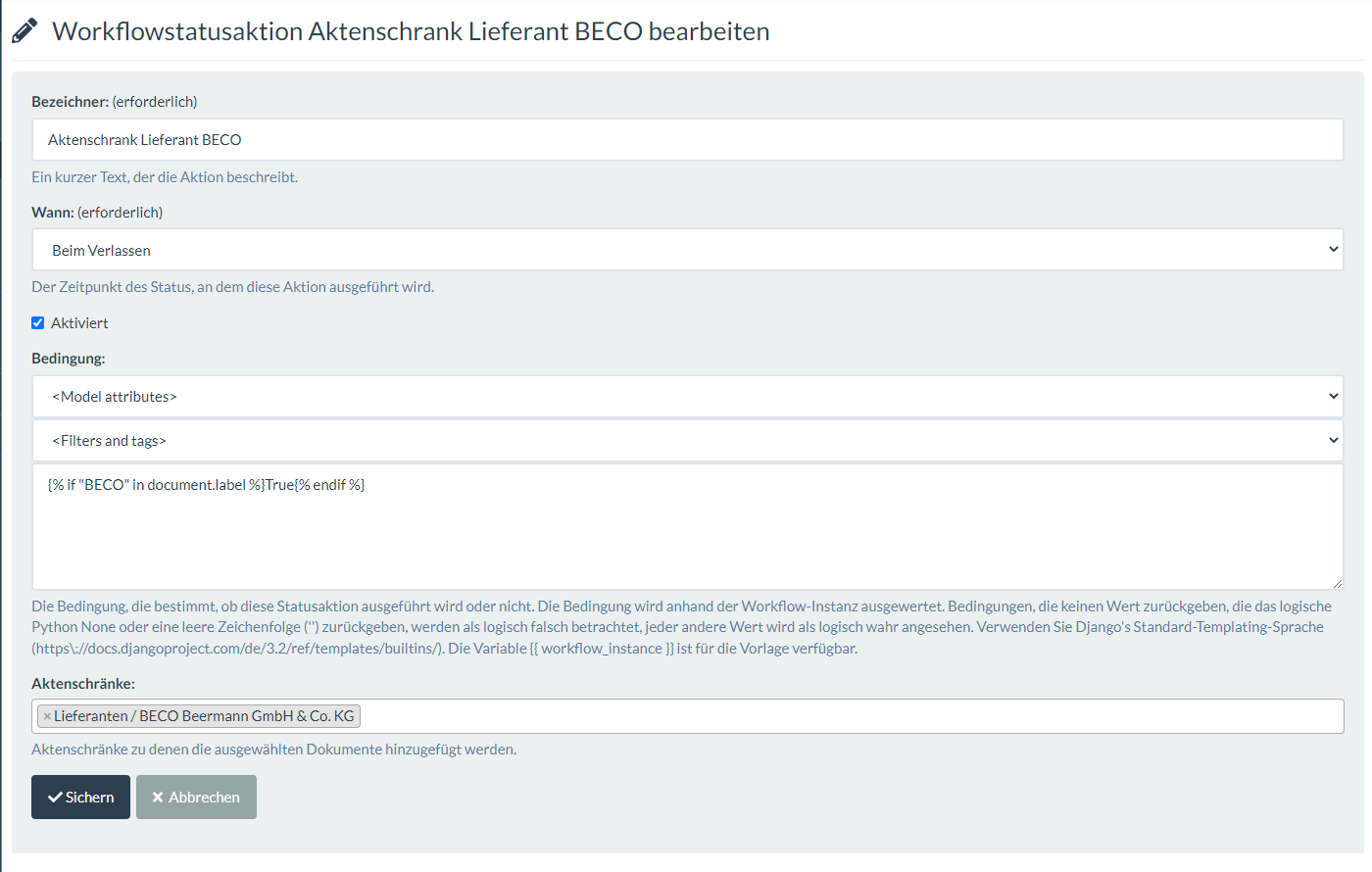
I didn’t want to start a new topic because I think this is related here. I have a really simple workflow which adds some metadata based on the filename to the document. This works well with the action (which doesn’t have a condition) to add the value from document label:
This doesn’t work. If I remove the condition, the document is added. So I think there is something wrong. In playground, I get “True” for the specific document for my if statement.