Resources and performace
If the installation is not parallelized and properly tuned, adding more resources won’t have much impact on real life performance. This is why Docker Compose became the default installation process. It allows tuning several aspects of the stack better than a direct install. A direct install inside a VM can’t make the most of the resources available. The single resource domain is going to cause one worker to take resources from the other workers. Performance artifact isolation happens only at the single OS host level as processes. For example the OCR tasks will slow down the entire VM. There is also no swap isolation.
Search engines
One of the tasks Worker B takes care of is indexing the search engine. Search engines are fast when retrieving data but are slow to update and use a lot of storage. That’s the trade off. Some search engines/libraries don’t support partial updates and as a compatibility measure, the entire object is reindexed when a change occurs, even for a single field. We’ve looked into deduplication of tasks and that’s one of the next improvements we plan to explore for the search system.
Another challenge is that search engines are not the same a database manager, and tend to be flat, support for object referencing, if any, is custom. This means that if a tag is attached to a document, Mayan needs to refresh the search index of the document as well as the index of the tag, completely as a single operation. If a tag that is attached to a document is renamed, the same thing happens. Now image a renaming a single tag attached to 100 documents. That’s at least 101 search indexes refreshes. The same problems applies to every single object in a Mayan installation. One modification to a single field can result in several hundred search refresh jobs, which is what you are seeing. This is the challenge when working with search engines and the reason we held this feature for as much as possible using the database as the search source, they are fast but many changes needs to be made to integrate them into a single seamless experience.
By default Mayan uses the Whoosh library as a search engine. Whoosh is easy to setup and get started but for better performance you can consider ElasticSearch. ElasticSearch runs as a separate service and isolated from Mayan. However the memory, CPU requirements, and maintenance requirements of ElasticSearch rivals those of Mayan itself. That’s the tradeoff, simple/easy/low resources vs. fast/complicated/high resources.
Performance tuning
It can take several days to fine tune a single installation to match your document patterns, usage pattern, and hardware specs. There is no single set of suggestions that will yield the same results for everybody. Even if we doubled or tripled the current team, it would still be impossible take time from the project tasks (this reply alone has taken about 30 minutes) to help fine tune installations. That is why support and fine tuning of installations is a paid service. It is the only way to be able to devote the time and resources (even external consultants for specialized topics) to improve an installation to work at its best. Besides the time and effort, technical support opens up a can of legal worms. There are legal and liability implications which require putting an agreement on paper.
Possibilities
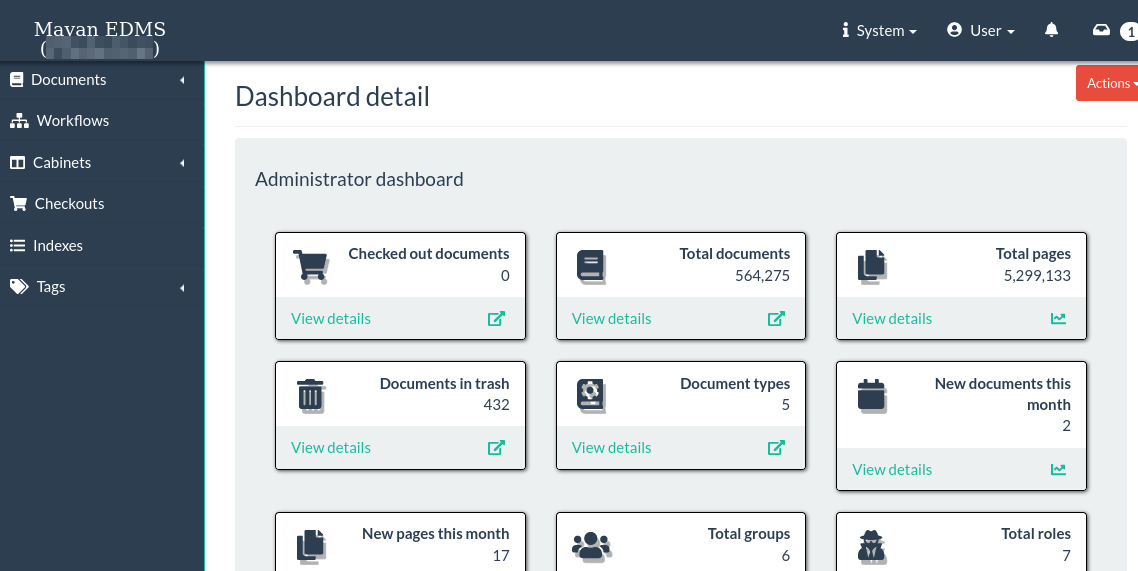
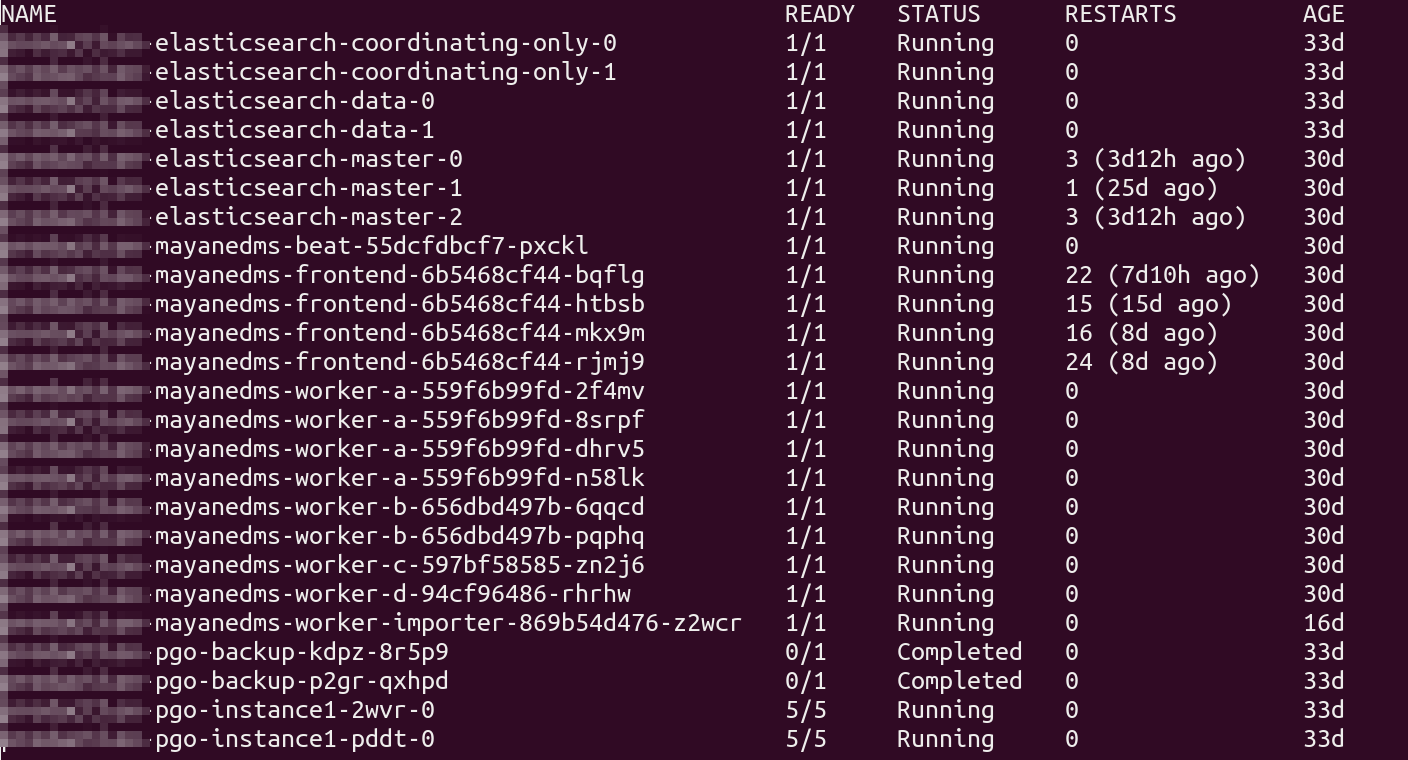
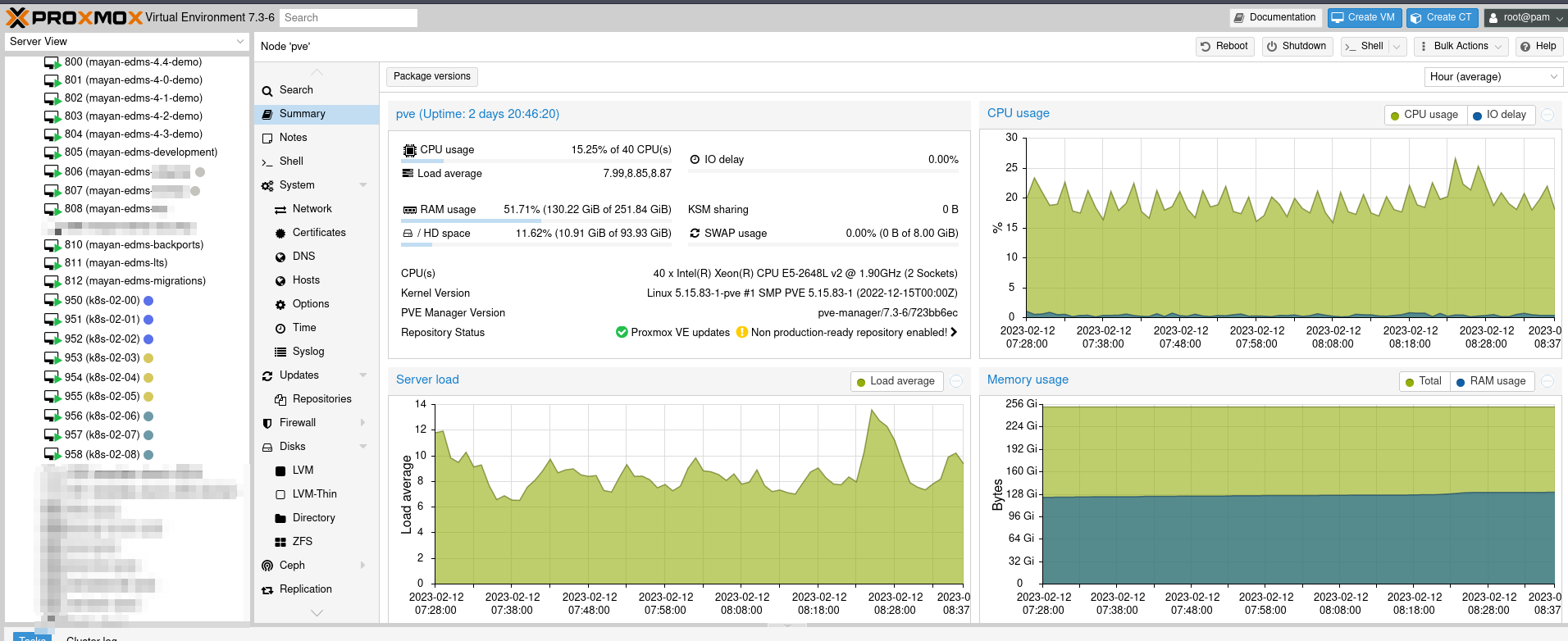
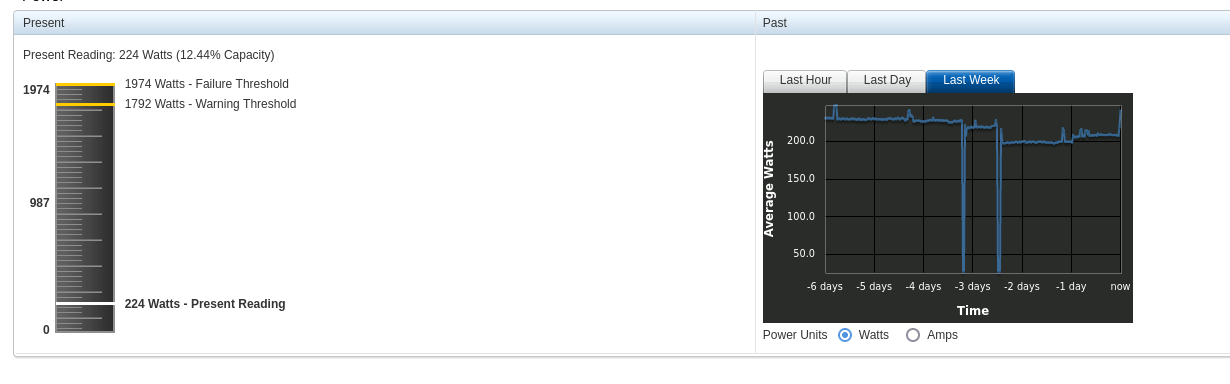
Taking the time and effort to fine tune Mayan can yield incredible results. As an example, any given time I have 10 or more Mayan installations running as development deployments, Docker Compose in VMs and Kubernetes deployments. Some of these installs have millions of pages and get stress tested around the clock. All of this is hosted along with my personal VMs, in a single R620 from 2012. This server is using low voltage E5-2648L v2 CPUs and remote NFS disks both are slow. Total server CPU load hovers at 20%. Power usage 200-300 watt range. This setup has taken months and is still a work in progress.