Wanted to post my findings to share with the community.
Friendly reminder that before you start mucking around with configuration, make a backup of the file(s) before you do!
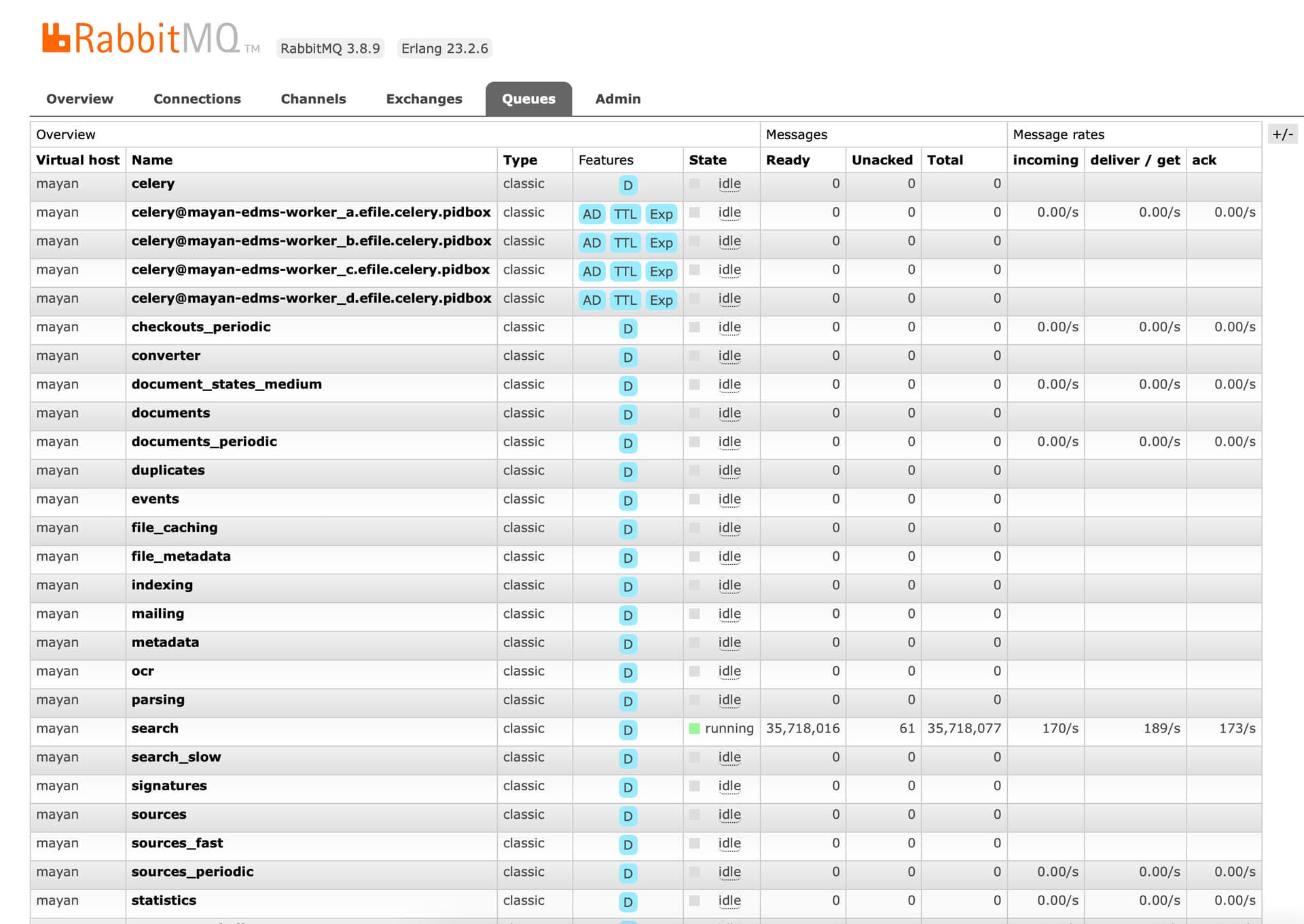
Armed with the knowlage that @roberto.rosario posted, I started with RabbitMQ Admin. By default the admin panel is turned off. So I had to enable it and create a user to access it. My googlefoo found this page describing how to do it.
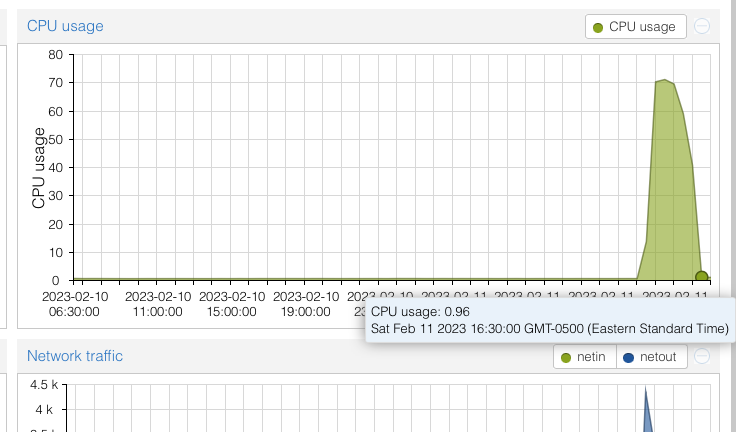
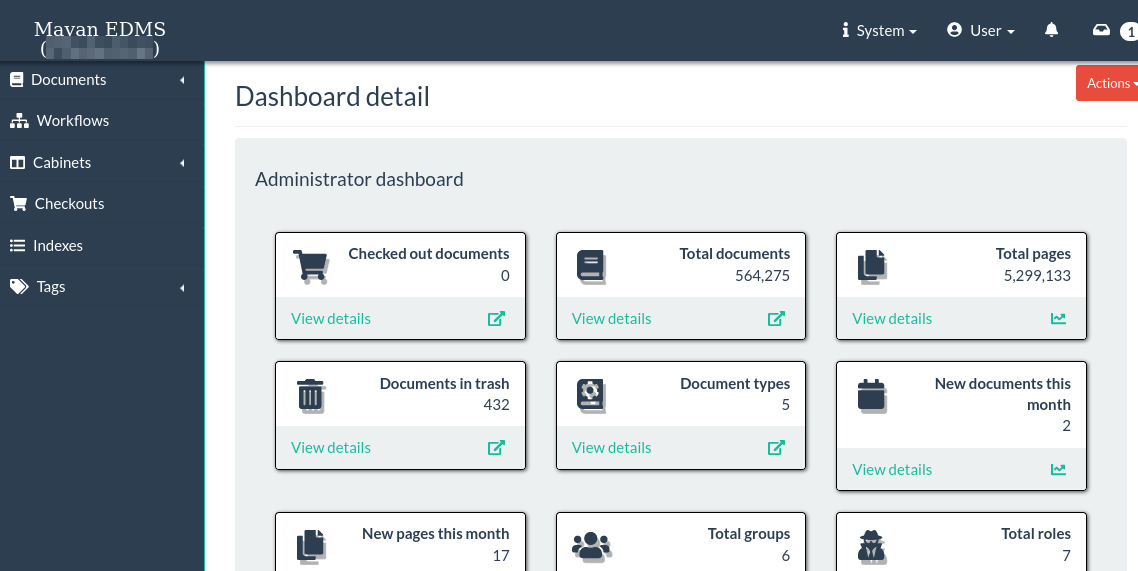
Once I enabled that and logged in I was able to see the queues and what was causing the high (50%) cpu rate. It was 90% but now I see all the OCR is done and looks like (I assume) its indexing the OCR text since the queue is called “search” correct me if Im wrong here.
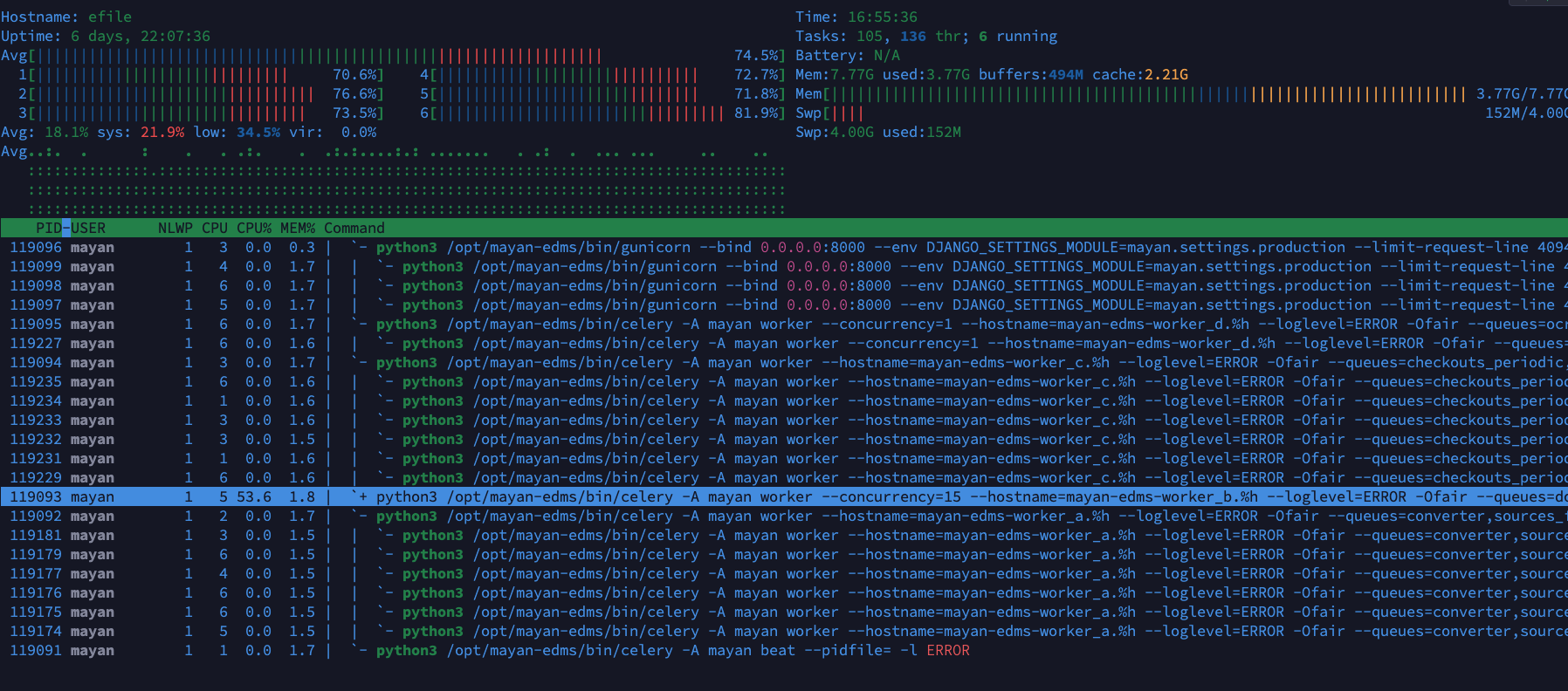
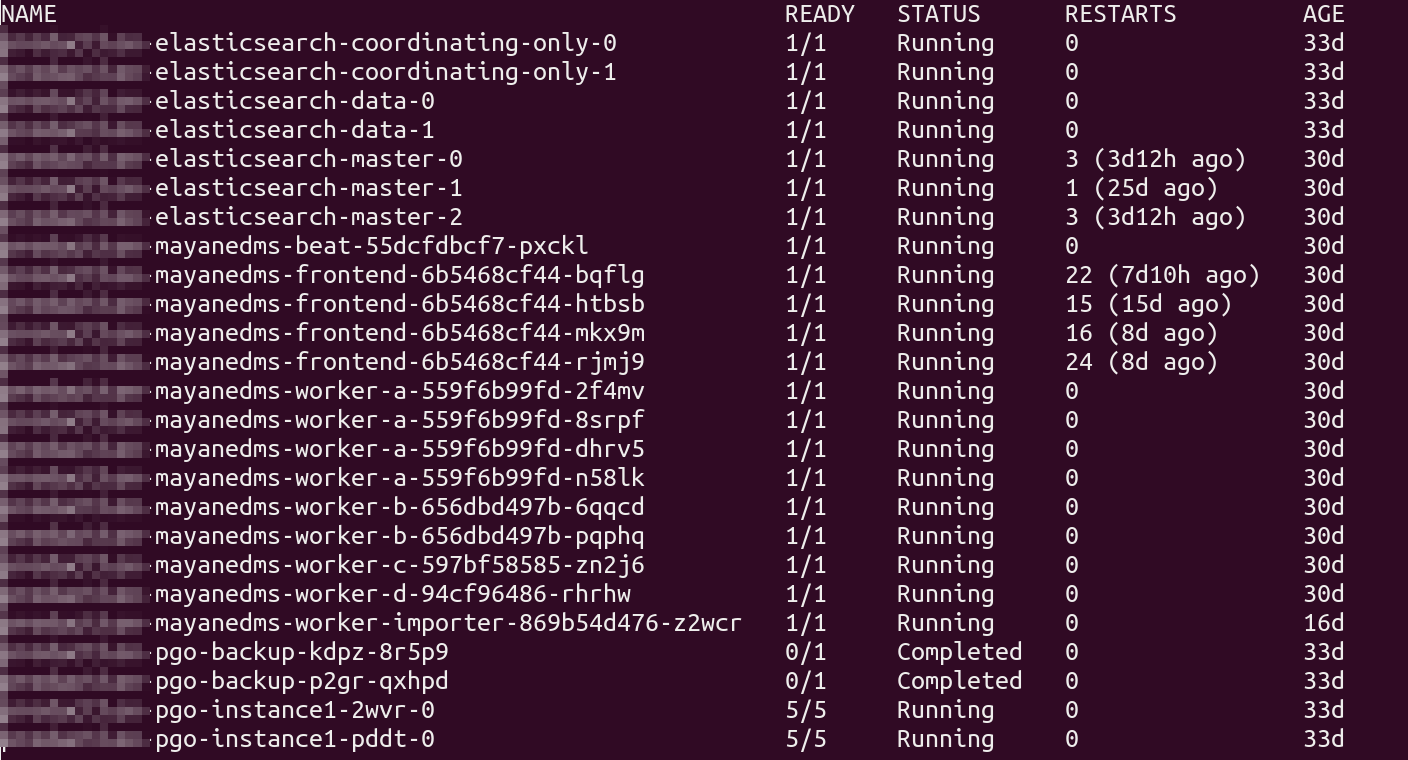
I did try and add more “B workers” by adjusting my supervisor config located at /etc/supervisor/conf.d/mayan.conf now granted I am using a “manual install” that as of now is not supported, so I would guss that being docker the config is environment variables. I set mine to 15 in my case that was the point where more than that did not make a difference. Also note the concurrency settings default value is the number of CPUs on the system.
While direct documentation of these settings can seem not easy to find, I searched the official documentation for MAYAN_WORKER_B_CONCURRENCY and found it here on the docs site with links to other documentation specifically for celery here. I did find that if you want to specify more “workers or concurrency” you have to add --concurrency=xx to the variable as its passed as a command line option. You can see part of my supervisor config below. Another note, probably only matters for manual installs, was I had to reload supervisor not just stop/start it so it re-reads the config file. I used htop to monitor the processes. see below screen shot as well.
I am not sure what the best ratio or workers to tasks would be, I assume that for each worker (concurrency) that each one can have 100 sub tasks? Just guessing here. I would assume also these values depending on the type of work being done as well.
# my config file /etc/supervisor/conf.d/mayan.conf on a manual install
...
[supervisord]
environment=
PYTHONPATH="/opt/mayan-edms/media/user_settings",
MAYAN_ALLOWED_HOSTS='["*"]',
MAYAN_MEDIA_ROOT="/opt/mayan-edms/media",
MAYAN_PYTHON_BIN_DIR=/opt/mayan-edms/bin/,
MAYAN_GUNICORN_BIN=/opt/mayan-edms/bin/gunicorn,
MAYAN_GUNICORN_LIMIT_REQUEST_LINE=4094,
MAYAN_GUNICORN_MAX_REQUESTS=500,
MAYAN_GUNICORN_REQUESTS_JITTER=50,
MAYAN_GUNICORN_TEMPORARY_DIRECTORY="",
MAYAN_GUNICORN_TIMEOUT=120,
MAYAN_GUNICORN_WORKER_CLASS=sync,
MAYAN_GUNICORN_WORKERS=3,
MAYAN_SETTINGS_MODULE=mayan.settings.production,
MAYAN_WORKER_A_CONCURRENCY="",
MAYAN_WORKER_A_MAX_MEMORY_PER_CHILD="--max-memory-per-child=300000",
MAYAN_WORKER_A_MAX_TASKS_PER_CHILD="--max-tasks-per-child=100",
MAYAN_WORKER_B_CONCURRENCY="--concurrency=15",
MAYAN_WORKER_B_MAX_MEMORY_PER_CHILD="--max-memory-per-child=300000",
MAYAN_WORKER_B_MAX_TASKS_PER_CHILD="--max-tasks-per-child=100",
MAYAN_WORKER_C_CONCURRENCY="",
MAYAN_WORKER_C_MAX_MEMORY_PER_CHILD="--max-memory-per-child=300000",
MAYAN_WORKER_C_MAX_TASKS_PER_CHILD="--max-tasks-per-child=100",
MAYAN_WORKER_D_CONCURRENCY="--concurrency=1",
MAYAN_WORKER_D_MAX_MEMORY_PER_CHILD="--max-memory-per-child=300000",
MAYAN_WORKER_D_MAX_TASKS_PER_CHILD="--max-tasks-per-child=5",
_LAST_LINE=""
...
with this knowlage I figure it will take another 24-48 hours before it’s all done.
Thanks again @roberto.rosario for the explanation and if I misspoke above in any of my assumptions let me know.