That seems to be working. I can see in the worker log that it gets to the point of contacting Mindee and times out. I’m assuming that’s a configuration error on my part.
I’ll verify my settings and try again.
That seems to be working. I can see in the worker log that it gets to the point of contacting Mindee and times out. I’m assuming that’s a configuration error on my part.
I’ll verify my settings and try again.
Well… it sort of works but they changed about every little piece of their python api since my last release…
I’m getting responses from the api but the response types are completely changed. I’m still figuring out how this all works now.
Yes, I double checked my settings, I’m pretty sure I have them right. I’m still getting the time out.
Sorry, it looks like I opened up a big can of worms on you. ![]()
Haha, yeah I wasn’t expecting that ![]() I just should have kept the old api version
I just should have kept the old api version ![]()
Well it needs to be done at some point so why not now ![]()
The good news is that I can already see that they prepared something to return the raw ocr data but it does not seem to be there yet.
Yay ![]()
It’s working for me now…
Take this as an example query:
docker exec -ti mayan-mayan-mindee-web-1 curl -X GET “http://localhost:8000/custom/Payroll/1799”
Replace Payroll with your api name and 1799 with your document id.
Note that currently the store_ocr property gets spammed with the complete api result which is not intended. I will fix that during the weekend. Also the standard APIs are still broken. I only fixed the custom api so far.
EDIT: also I saw that apparently they added classification fields for which you can define custom categories. That sounds very interesting. I will look into that as well since this is something I really need but haven’t found a solution for yet ![]()
Thank you for working so quickly to update the plugins!
Unfortunately I’m still getting a timeout connecting to Mindee. I’m sure I’m doing something wrong, I just don’t know what.
I can’t get any insight from the logs where the connection is failing.
Here’s the line where it times out.
File "/usr/local/lib/python3.12/site-packages/urllib3/util/connection.py", line 73, in create_connection
sock.connect(sa)
File "/usr/local/lib/python3.12/site-packages/rq/timeouts.py", line 63, in handle_death_penalty
raise self._exception('Task exceeded maximum timeout value ({0} seconds)'.format(self._timeout))
rq.timeouts.JobTimeoutException: Task exceeded maximum timeout value (180 seconds)
Hmmm… this looks odd. The exception seems to come from your redis queue and it also says timeout 0 seconds. So it seems to me that the worker does not get enough time to execute its task. I couldn’t even tell you where to configure this but have you changed some timeouts for redis recently?
EDIT: oh no it says 180 seconds… hm ![]()
What’s last in the logs before this happens?
How big is the document you’re downloading from Mayan? How many pages?
Sorry for the confusion. It took me a while, but I figured out the above time out problem. The mayan-mindee-work container had no access to an external network. Just the mayan network. Once I added my reverse proxy network to the container it could connect to Mindee.
But now I’m getting an error about Mindee not supporting synchronous mode
File "/usr/local/lib/python3.12/site-packages/mindee/client.py", line 336, in _make_request
raise handle_error(
mindee.error.mindee_http_error.MindeeHTTPClientError: custom 403 HTTP error: mindee/invoice-12-demo does not support sync mode - This product does not support synchronous mode
Ok I see. They added support to parse documents asynchronously which is not yet supported by my plugin. Seems easy to fix that though since the methods for asynchronous parsing are all in the new python sdk. It seems that this also relates to the provision more data by the api. It seems to be possible to retrieve the complete ocr data in the asynchronous mode. The asynchronous request feature does not seem to be documented until now though but it’s in the code already so I will give it a try. I see that they also implemented the cutting of excess pages so I can also remove this logic from my plugin.
You can try again now. The default is now that asynchronous mode is used. My api does not support this however, probably because it’s older. So there is a url parameter you can pass to the url when calling the service by attaching “?sychronous=True” for APIs that do not support this.
Thank you again for working so quickly on solving these issues. I really appreciate it.
I don’t have success yet, but we are getting closer.
I get this error at the end of the log.
2024-01-06 14:00:02,267 worker INFO Loading document 88
2024-01-06 14:00:02,267 mayanapi DEBUG endpoint api call http://frontend:8000/api/v4/documents/88/?
File "/usr/local/lib/python3.12/site-packages/mindee/parsing/custom/classification.py", line 14, in __init__
self.confidence = raw_prediction["confidence"]
~~~~~~~~~~~~~~^^^^^^^^^^^^^^
KeyError: 'confidence'
Hmmm, that’s an error in the mindee sdk. Apparently it fails to map the confidence value from a classification field. I guess the best you can do is to file a bug report in their repo:
https://github.com/mindee/mindee-api-python
There have been a couple of commits since the last release so maybe this was already fixed in the meantime. But I don’t see a commit message that matches this problem.
I’m still wondering about this one. I created a new custom api today and it also does not work in asynchronous mode but only synchronously. How did you do that? ![]()
I’m not getting the error you have on mapping the classification field but of course I cannot test this in the asynchronous mode without an api.
I’m looking at the API Documentation for my API. I see the Confidence Schema, has a Capital C

I don’t know if that’s critical.
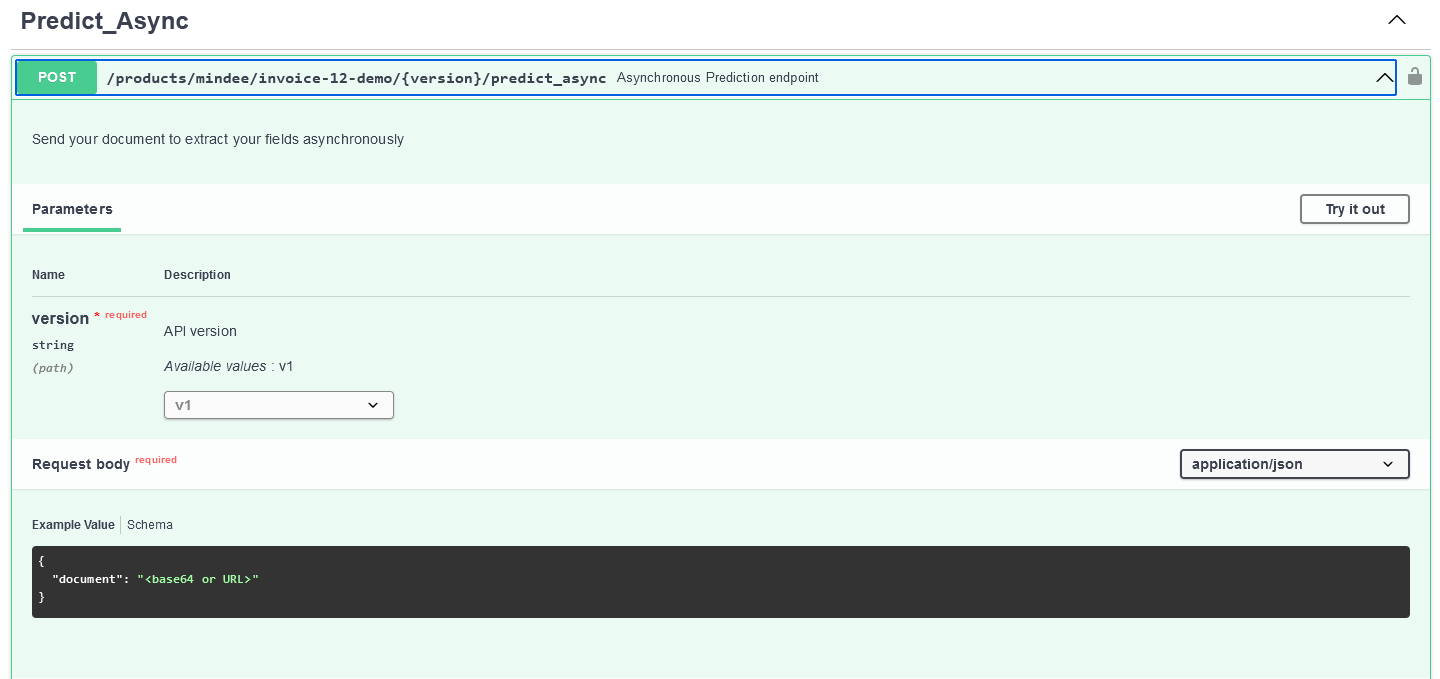
I also see there is a Predict_Async API Call
I don’t have that. I also see in your url that it starts with /products/mindee where I have my own user name instead of mindee. Did you somehow manage to build your own invoice api on top of theirs? I could not find a way to do that?!
The capital C could be enough to cause these problems, I don’t know though if that is the case ![]()
We have a trial account, and this is an api that they made for us.
invoice-12-demo
That’s why it’s mindee and not our name. Once we get this working, we we’re going to sign up for their services, as we have 10 of thousands of documents to scan.
Ok I see. I just have a free account and created my custom APIs with the api builder on their website. These custom APIs do not support the asynchronous mode. So I cannot really test this on my end. But since this seems to be a problem in their python implementation anyway they should be able to fix that.
Note that I added a new config field „model“ in the api.json file. The documentation says this is required since the default is „1“. I have my doubts that this is really the case but I added it just to make sure you can choose which version will be used.
I’ve reached out to my contact at Mindee. I explained what issues we’ve run into. He will be forwarding that to the engineering team, and get back to me.
Hi Thomas,
I spoke to one of the Developers at Mindee today. They are going through a major revamp of their API and Python SDK. They expect to have it finished in a few weeks. Once it’s finished they will let me know. Also they said you can watch the SDK github project to see their progress.
They were very friendly and helpful. They offered their help for you as well. If you would like to contact them, I can give you their information.
Thanks,
Daniel
Hi Daniel,
thank you for this heads up. So I’ll probably have to be prepared for more SDK changes. It’s very kind that they offered help but I’m actually not a business customer so they won’t be able to sell much to me ![]()
I think I’m good for now, my plugin is fully working with the current state of the SDK and I’m looking forward for new features in their products ![]()
Thomas