Dear Mayan Users and Creators! ![]()
(Note: I am no expert regarding Docker or Elasticsearch in general, so please forgive me, if I am overlooking something obvious)
I am currently running MayanEDMS version 4.4 via docker-compose on a remote server (with traefik set up). After browsing some time, I realised that the current Search backend (Whoosh per default, since 4.2, I reckon) does not seem to properly work for me.
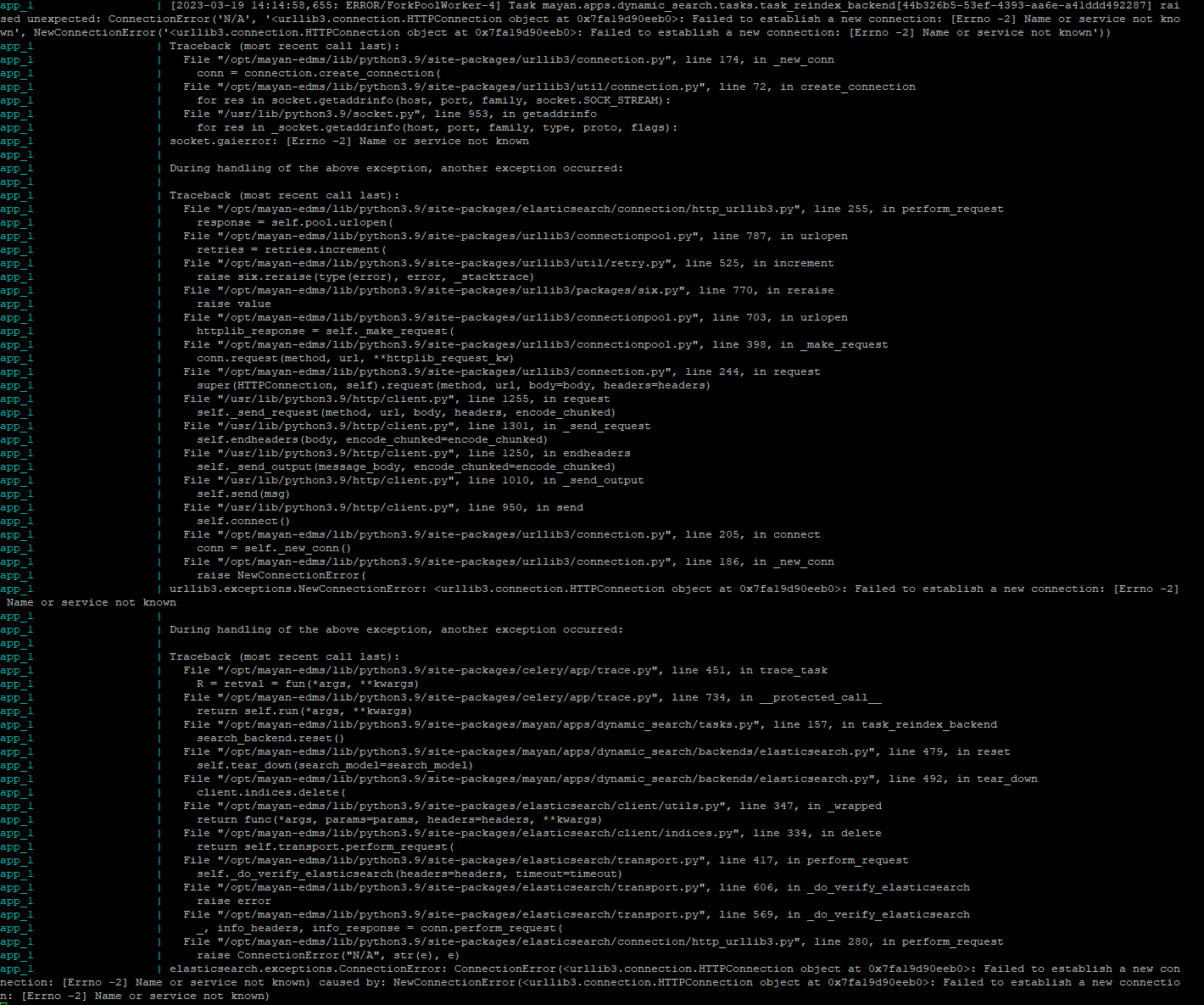
Since I actually want to use Elasticsearch, that was not that big of deal, but the real problem is that I can not seem to get Elasticsearch to work. From what I can tell, it is mentioned in the docker-compose per default, which should state, that there is at least a running instance of the Elasticsearch service. The actual problems/errors occur when I change the Search backend to Elasticsearch and try to search: I am getting the following error (as a pop-up in MayanEDMS):
Search backend error. Verify that the search service is available and that the search syntax is valid for the active search backend; ConnectionError(<urllib3.connection.HTTPConnection object at 0x7fe226ec0160>: Failed to establish a new connection: [Errno 111] Connection refused) caused by: NewConnectionError(<urllib3.connection.HTTPConnection object at 0x7fe226ec0160>: Failed to establish a new connection: [Errno 111] Connection refused)
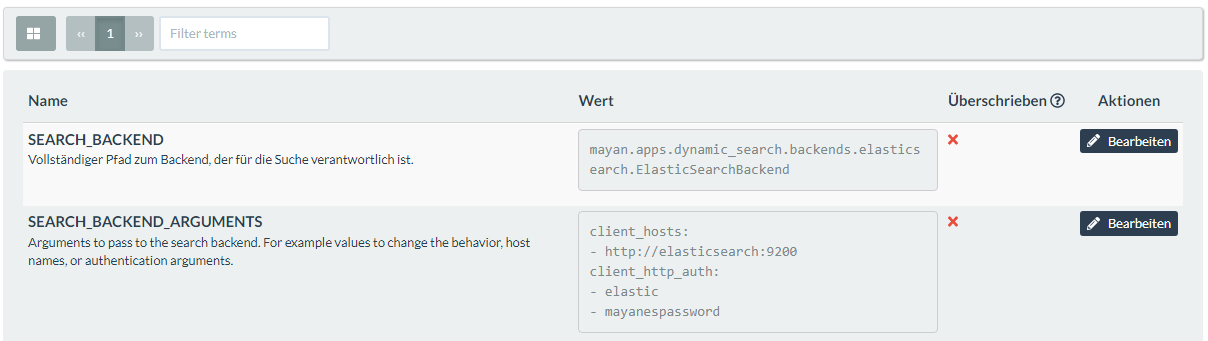
Regarding this error I tried to fix it with the SEARCH_BACKEND_ARGUMENTS as mentioned in the following issue on Gitlab (Add documentation for Elasticsearch and Docker Compose (#1092) · Issues · Mayan EDMS / Mayan EDMS · GitLab), but I can not seem to figure out, what exactly I have to state. Especially the client_hosts is unclear for me, since I have traefik running - on the client_http_auth side, I believe that I used the correct credentials (just the default ones, since I did not change them - ‘client_http_auth’:[‘elastic’,‘mayanespasswords’]).
If someone would be so nice, to guide me through the correct setup of Elasticsearch, I would be very thankful. I am looking forward to your ideas/answers.
Thank you in advance,
Alex
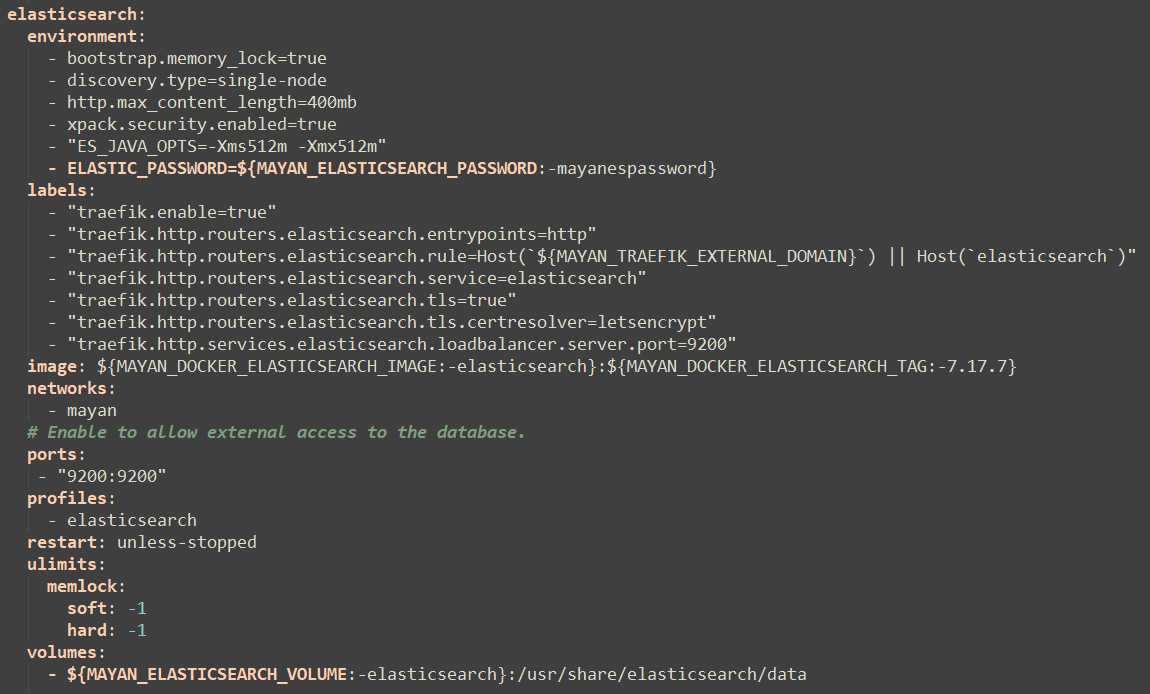

 I missed the profile (or the daemon.js, or all together), so it seems to be working just fine now, from what I can tell from a few test searches.
I missed the profile (or the daemon.js, or all together), so it seems to be working just fine now, from what I can tell from a few test searches.